Finding Dependencies based on Text Patterns
“And a thing is not seen because it is visible, but conversely, visible because it is seen” ― Socrates
Sokrates analyses dependencies through simple text patterns searches. Such dependency analyses are not as detailed as the ones provided by specialized software tools.
Sokrates focuses on finding dependencies between components and is not concerned with more detailed insights. There are are two main reasons for this. First, dependencies among the components are, from an architectural standpoint, the most relevant ones. While it may be interesting to know all dependencies between individual files or between units, what I miss the most in practice is the big picture, and Sokrates focuses exclusively on the big picture. Moreover, once when you understand the big picture, you can reliably obtain more detailed dependency data from your IDEs and code editors. Second, by concentrating on finding only the dependencies among components, you can simplify analysis and use simple heuristics with high accuracy.
Sokrates’ pattern-based dependency analysis requires the existence of easily identifiable textual patterns that both, uniquely connect files in a shared component, and are present in places where there is a link, a dependency, to another component. Consequently, if such patterns do not exist if they are not unique or are challenging to find, you may not be able to identify the dependencies reliably.
While limited at the detail level, the pattern-based identification of the dependencies is an extremely flexible and powerful mechanism that I have been using daily for years and with great success. For most languages, such analysis can replicate the level of accuracy that a more advanced and sophisticated static-code analysis tools analysis offer. But, if used wisely and with care, it also has some additional features, going beyond static code analysis tools. Such features include the possibility to identify dependencies entities defined in text constants or comments, such as dependencies to websites, APIs, or database tables, that regular classical static code analysis tools do not cover.
Sokrates uses pattern-based dependency analysis in two places. The first place is the internal built-in dependency finders. Sokrates has several built-in dependency finders for mainstream programming languages so that you can get a basic dependency analysis of these languages for them without any extra configuration. The second place is a manual configuration, where you can define your own dependency finders based on the Sokrates pattern-based mechanisms. If a programming language supports build-in dependency finders, you can still use your custom dependency finders, and switch off the built-in ones.
Build-in Pattern-Based Dependency Finders
For several common languages, Sokrates includes the build-in pattern-based dependency finders. You can switch these build-in finders and use your own configured finders. Here, I’ll describe a few heuristics used to define patter dependencies in Sokrates build-in dependency finders.
The following pattern-based heuristics are used in languages where files are organized in explicitly defined packages, modules or namespaces (e.g., Java, C#, Go, Scala, PHP, Groovy, Kotlin, Perl, Ruby, D):
- The Sokrates analysis assumes that the names of packages, modules or namespaces are present in source files, and are unique among components (e.g., two components do not contain the same package, module or namespace), If the same package, module or namespace is defined in two or more components, then Sokrates analysis may generate false positives.
- Sokrates looks for component patterns: modules or namespaces definitions, generally at the beginning of the file. Sokrates then extract the full name of a package, module, or namespace and uses it as one of the identifiers for a component.
- Sokrates then looks for dependencies by looking for import statements to packages, modules, or namespaces. If the full name in the import statement can be found in package statements on the other component, then Sokrates adds a dependency to that component.
Figure 1 illustrates the working od a Java build-in dependency finder.
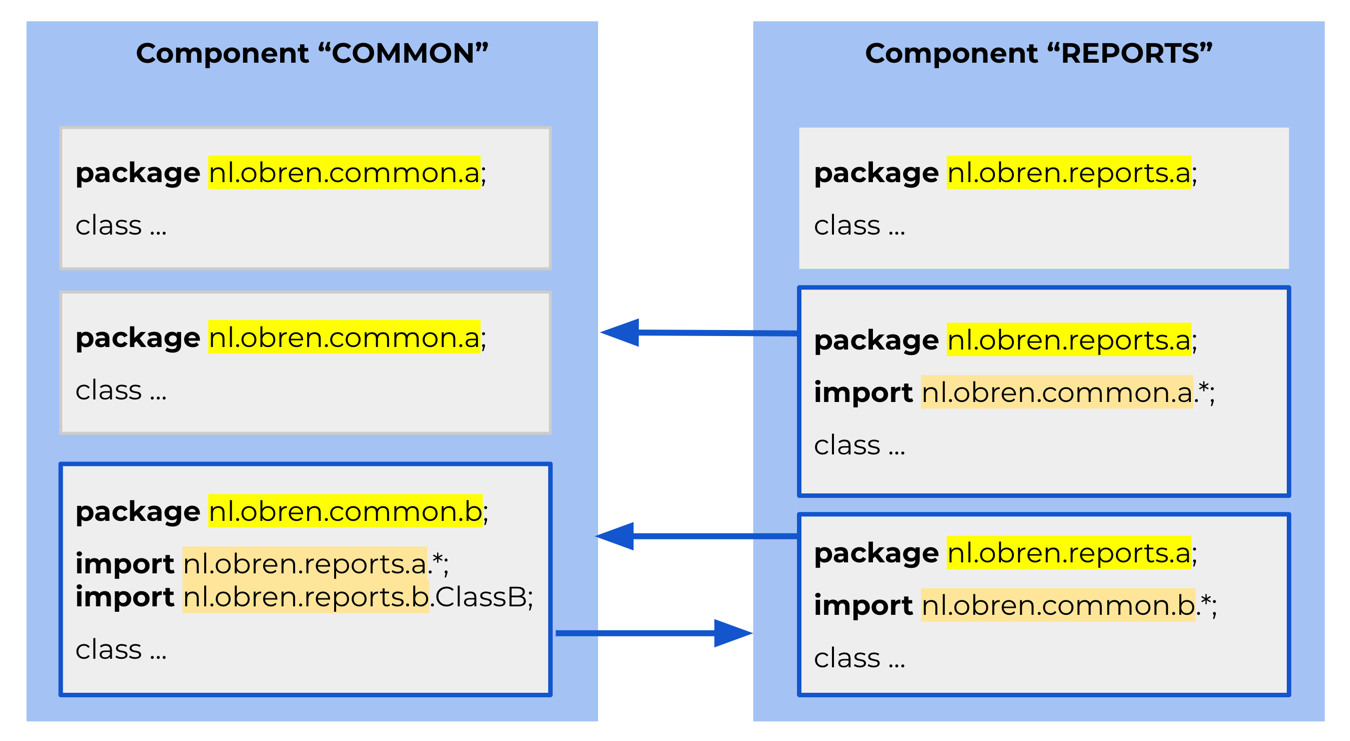
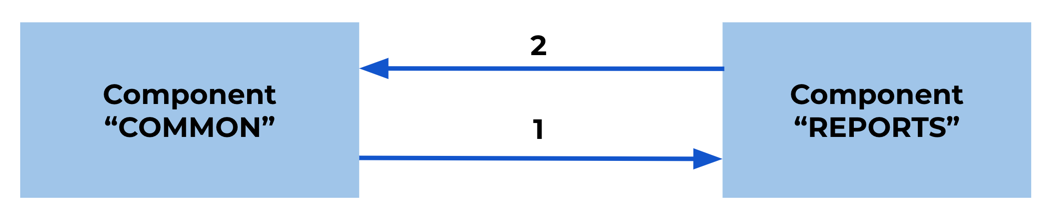
Figure 1: An overview of the build-in Java pattern-based dependency extractor. Sokrates uses Java package definitions as patterns to connect components. The number on the link represents the number of files that contain a pattern that represents a dependent component (in our case a package name).
Custom Dependency Finders
You can use a configuration object within the logical decomposition section of the configuration file to define a custom dependency finder. This custom dependency finder section enables you to set a string transformation scripts that takes as an input a path or a line of file content and transforms the input string into a name. If this name matches the name of any component, then Sokrates creates a link between the file and the component. If the name does not match any component names, Sokrates treats the name as the name of an external component. Sokrates displays the names of external components with grey color, to distinguish them from internal components.
Custom Dependency Finders: Linking Path-Based Componentization to Path-Based Include Statements
With the Sokrates configuration file, you can define your own pattern based dependency finders using the Sokrates String Transformation Language (SSTL). The key to this approach is defining a string transformation that maps a path or content of a file to a name of a component. For instance, let’s assume that we have a project with the following source code folders (Figure 2).
src/
vs/
base/
browser/
common/
node/
parts/
worker/
Figure 2: An example folder structure taken from the VS Code project.
Let’s also assume that we have componentized this project based on the folder depth at level 3 (src/vs/base/*). Figure 3 shows the componentization that, for our example, creates five components.

Figure 3: The fragment of Sokrates report displaying the result of the folder-depth based componentization (level 3) of the source code structure described in Figure 2.
The files in this folder are TypeScript files, and they import other TypesScript file vai import statement that user path-based referencing. I have identified the following convention that we can use to connect files from one component to files in other components:
- look for all files with path like “.[.]ts” AND content like “import .from ‘vs/base.*”
- for each file matching the previous criteria, extract, from the matched content lines, the following regex pattern “base(/[a-zA-Z0-9_]+|)”
- in the extracted string replace “base(/)?” with “” (empty string)
Figure 4 shows the JSON from the Sokrates configuration file the described steps.
{
"dependenciesFinder": {
"useBuiltInDependencyFinders": false,
"rules": [],
"metaRules": [
{
"pathPattern": ".*[.]ts",
"contentPattern": "import .*from 'vs/base.*",
"use": "content",
"ignoreComments": false,
"nameOperations": [
{
"op": "extract",
"params": [
"base(/[a-zA-Z0-9_]+|)"
]
},
{
"op": "replace",
"params": [
"base(/)?",
""
]
}
]
}
]
}
}Figure 4: A fragment of a Sokrates configuration file defining a pattern-based dependency finder.
When applied to the files, this leads to the dependency diagram shown in Figure 5 (the key is to transform import statements lines to get a string that matches the names of components obtained by path-based componentization).
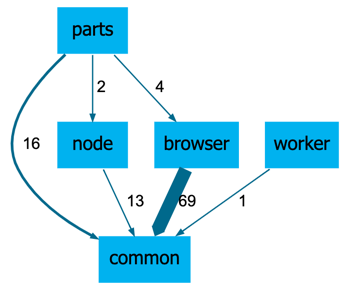
Figure 5: A visualization of measured dependencies.
Sokrates also stores the evidence, actual content fragment that Sokrates used to define a dependency. Figure 6 shows the details of the “browser – common” dependencies.
from: browser
to: common
evidence:
- file: "src/vs/base/browser/browser.ts"
contains "import { Emitter, Event } from 'vs/base/common/event';"
from: browser
to: common
evidence:
- file: "src/vs/base/browser/canIUse.ts"
contains "import * as platform from 'vs/base/common/platform';"
from: browser
to: common
evidence:
- file: "src/vs/base/browser/contextmenu.ts"
contains "import { IAction, IActionRunner } from 'vs/base/common/actions';"
from: browser
to: common
evidence:
- file: "src/vs/base/browser/dnd.ts"
contains "import { Disposable } from 'vs/base/common/lifecycle';"
from: browser
to: common
evidence:
- file: "src/vs/base/browser/dom.ts"
contains "import { TimeoutTimer } from 'vs/base/common/async';"
...
Figure 6: A fragment of a Sokrates’ details file for dependencies from Figure 4. The file lists each dependency, as well as the content due to which Sokrates has decided to create a dependency.
Custom Dependency Finders: Linking Namespace Componentization to Namespace Import Statements
You can implement your own dependencies finder in a similar way as Sokrates implements package based built-in finders. For that purpose you need to define two things in a Sokrates configuration file:
- a componentization based on file content (the name of a component is derived based on a file content)
- a dependency finder based on a file content (the name of a dependant component is derived based on a file content)
An example that I show here illustrates how to define these two elements for Java project, where a Java package is used as a component name. Figure 7 shows a fragment from a Sokrates configuration file illustrating dynamic componentization, where the name of a component in which a file is derived from the package name in which the file resides. Figure 8 shows another fragment from a Sokrates configuration file illustrating how to derive dependencies based on import statements to packages so that the name of components in dependencies matches the names of components from the componentization.
{
"pathPattern": ".*[.]java",
"contentPattern": "package nl[.]obren[.]sokrates[.].*",
"use": "content",
"ignoreComments": true,
"nameOperations": [
{
"op": "extract",
"params": [
"nl[.]obren[.]sokrates[.][a-zA-Z0-9_]+[.][a-zA-Z0-9_]+"
]
},
{
"op": "replace",
"params": [
"nl[.]obren[.]sokrates[.]",
""
]
}
]
}Figure 7: A fragment of a Sokrates configuration file defining component from Java package statements.
{
"pathPattern": ".*[.]java",
"contentPattern": "import nl[.]obren[.]sokrates[.].*",
"use": "content",
"ignoreComments": true,
"nameOperations": [
{
"op": "extract",
"params": [
"nl[.]obren[.]sokrates[.][a-zA-Z0-9_]+[.][a-zA-Z0-9_]+"
]
},
{
"op": "replace",
"params": [
"nl[.]obren[.]sokrates[.]",
""
]
}
]
}Figure 8: A fragment of a Sokrates configuration file defining links to components from Java import statements.
Figure 9 shows the resulting dependency graph based on the configuration from Figures 7 and 8 when applied on the Sokrates source code.
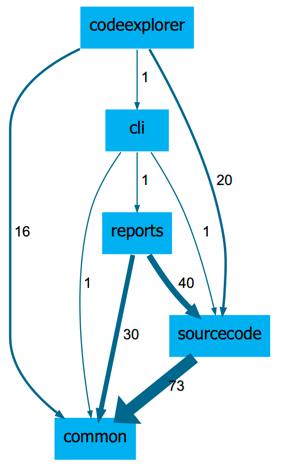
Figure 9: The resulting dependency graph based on the configuration from Figure 7 and 8.
Custom Dependency Finders: Identifying External Links
You can also use custom dependency finders to find links to external components, such as external sites, APIs, or database tables. If Sokrates custom dependency finder gets the name of the component that does not match the component names defined in componentization, then Sokrates renders this “non-existent” component as external (grey color on dependency graphs). For example, while analyzing the VS Code project, we used this feature to find links to GitHub repositories from which VS code has reused the grammar or other programming language settings. Code this purpose we have defined a simple dependency finder, with the following script (Figure 10 shows the JSON fragment of this script implementing this logic)
- find files with content like “.github[.]com/[a-zA-Z0-9-_]+/[a-zA-Z0-9-_]+.”
- from the matching content line extract (“github[.]com/[a-zA-Z0-9-_]+/[a-zA-Z0-9-_]+”)
{
"dependenciesFinder": {
"useBuiltInDependencyFinders": true,
"rules": [],
"metaRules": [
{
"pathPattern": "",
"contentPattern": ".*github[.]com/[a-zA-Z0-9\\-_]+/[a-zA-Z0-9\\-_]+.*",
"use": "content",
"ignoreComments": false,
"nameOperations": [
{
"op": "extract",
"params": [
"github[.]com/[a-zA-Z0-9\\-_]+/[a-zA-Z0-9\\-_]+"
]
}
]
}
]
}
}Figure 10: A A fragment of the VS Code Sokrates configuration file defining a dependency finder for links to external GitHub projects.
Figure 11 shows the resulting dependency graph, and Figure 12 shows a few samples of Sokrates evidence for dependencies.
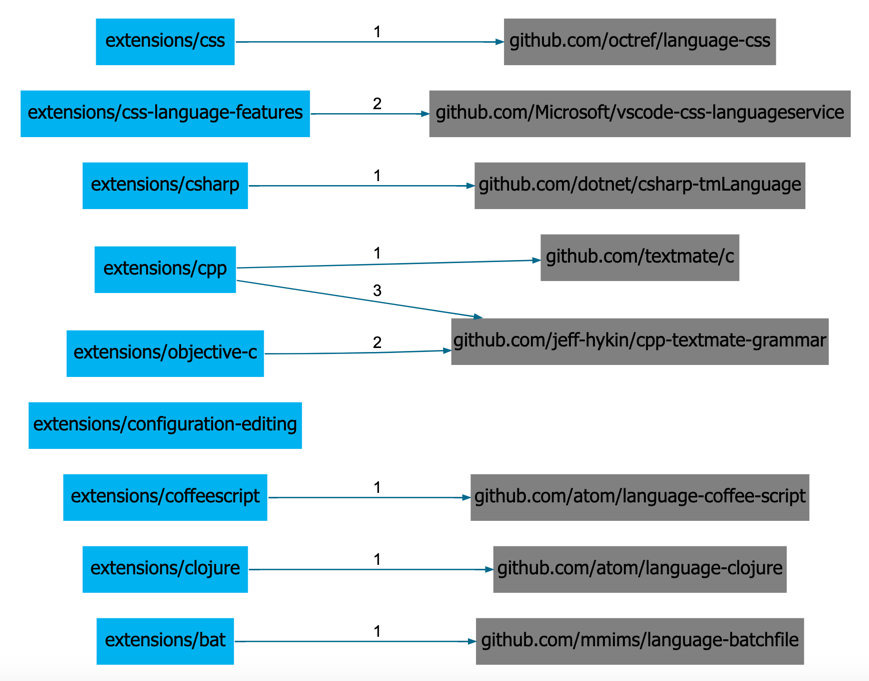
Figure 11: A visualization of the measured GitHub project dependencies in the VS Code project. The measurements extract links from VS Code comments.
VS Code Components and Dependecies
from: extensions/html-language-features to: github.com/Microsoft/vscode-html-languageservice evidence: - file: "extensions/html-language-features/package.nls.json" contains " "html.customData.desc": "A list of relative file paths pointing to JSON files following the [custom data format](https://github.com/Microsoft/vscode-html-languageservice/blob/master/docs/customData.md).\n\nVS Code loads custom data on startup to enhance its HTML support for the custom HTML tags, attributes and attribute values you specify in the JSON files.\n\nThe file paths are relative to workspace and only workspace folder settings are considered."," from: extensions/html-language-features to: github.com/Microsoft/vscode-html-languageservice evidence: - file: "extensions/html-language-features/schemas/package.schema.json" contains " "markdownDescription": "A list of relative file paths pointing to JSON files following the [custom data format](https://github.com/Microsoft/vscode-html-languageservice/blob/master/docs/customData.md).\n\nVS Code loads custom data on startup to enhance its HTML support for the custom HTML tags, attributes and attribute values you specify in the JSON files.\n\nThe file paths are relative to workspace and only workspace folder settings are considered.","
Figure 12: A fragment of a Sokrates’ details file for dependencies from Figure 11. The file lists each dependency, as well as the content due to which Sokrates has decided to create a dependency.